Censorship Industrial Complex
Elon Musk skewers Trudeau gov’t Online Harms bill as ‘insane’ for targeting speech retroactively


From LifeSiteNews

It literally spits in the face of all Western legal traditions, especially the one about only being punished if you infringed on a law that was valid at the time of committing a crime
Billionaire tech mogul Elon Musk remarked that it is “insane” that the Trudeau government’s proposed “Online Harms” bill would target internet speech retroactively if it becomes law.
“This sounds insane if accurate!” wrote Musk on Tuesday, in reply to an X (formerly Twitter) user named Camus who detailed that Prime Minister Justin Trudeau’s government’s Bill C-63, the Online Harms Act, could see Canadians fined or even jailed for things posted on the internet prior to the bill becoming law.
Camus noted how Bill C-63 could give police “the power to retroactively search the Internet for ‘hate speech’ violations and arrest offenders, even if the offence occurred before the law existed.”
A brief time later, X’s “CommunityNotes” program – a system in which users collectively “fact-check” information shared on the site –confirmed what Camus had written was accurate, quoting a section of the bill’s text.
“Part 3 of Bill C-63, which is still at first reading stage and is not yet law, adds to the Canadian Human Rights Act: ‘a person communicates or causes to be communicated hate speech so long as the hate speech remains public and the person can remove or block access to it,’” CommunityNotes wrote.
Camus observed about Bill C-63 that the “Trudeau regime has introduced an Orwellian new law.”
“This new bill is aimed at safeguarding the masses from so-called ‘hate speech,’” he wrote. “The real shocker in this bill is the alarming retroactive aspect. Essentially, whatever you’ve said in the past can now be weaponized against you by today’s draconian standards.”
Camus observed how historian Dr. Muriel Blaive has weighed in on “this draconian law,” labeling it outright “mad.”
“She points out how it literally spits in the face of all Western legal traditions, especially the one about only being punished if you infringed on a law that was valid at the time of committing a crime,” wrote Camus.
Bill C-63 was introduced by Liberal Minster Attorney General Arif Virani on February 26 and was immediately blasted by constitutional experts as troublesome.
The bill, if passed, will modify existing laws, amend the Criminal Code as well as the Canadian Human Rights Act, in what the Liberals claim will target certain cases of internet content removal, notably those involving child sexual abuse and pornography.
However, the bill also seeks to police “hate” speech online with broad definitions, severe penalties, and dubious tactics.
Trudeau’s new bill a ‘terrible attack’ on speech, Musk warns
On Tuesday, well-known Canadian psychologist Jordan Peterson replied to Musk by saying about Bill C-63, “It’s much much worse than you have been informed: plans to shackle Canadians electronically if accusers fear a ‘hate crime’ might (might) be committed.”
“It’s the most Orwellian piece of legislation ever promoted in the West.”
Musk replied to Peterson by saying Bill C-63 is “[a] terrible attack on the rights of Canadians to speak freely!”
Other notable X users, such as Canadian lawyer David Freiheit, who is known online as Viva Frei, confirmed Musk’s concern that Bill C-63 could go after X users from posts/tweets made long ago.
“It’s pretty close to accurate, Elon. If someone has the ability to delete a ‘hate speech’ tweet / post and does not, and someone else retweets that tweet, it would qualify as ‘publication’ under the law and be sanctionable,” he wrote.
Details of the new legislation to regulate the internet show the bill could lead to more people jailed for life for “hate crimes” or fined $50,000 and jailed for posts that the government defines as “hate speech” based on gender, race, or other categories.
The bill also calls for the creation of a digital safety commission, a digital safety ombudsperson, and a digital safety office.
The Justice Centre for Constitutional Freedoms (JCCF) has said Bill C-63 is “the most serious threat to free expression in Canada in generations. This terrible federal legislation, Bill C -63, would empower the Canadian Human Rights Commission to prosecute Canadians over non-criminal hate speech.”
In a recent podcast, Peterson and Queen’s University law professor Bruce Pardy warned of the “totalitarian” impact Trudeau’s new Online Harms bill will have on Canada.
Peterson observed that the Trudeau government is effectively “establishing an entirely new bureaucracy” with an “unspecified range of power with non-specific purview that purports to protect children from online exploitation” but has the possibility of turning itself into an internet “policing state.”
 MxM News
MxM News
Newly Revealed Documents Confirm Lab Leak Coverup
Quick Hit:
The global debate over COVID-19’s origins has taken a dramatic turn after newly uncovered reports indicate that intelligence agencies in Germany had determined with near certainty that the virus originated in a Chinese lab as early as 2020. Despite this revelation, German Chancellor Angela Merkel reportedly chose to suppress the findings, aligning with a broader pattern of obfuscation by Western governments and media outlets.
Key Details:
-
German newspapers Zeit and Süddeutsche Zeitung reported that Germany’s intelligence agency, the BND, concluded in early 2020 with 80% to 95% certainty that COVID-19 leaked from a lab in Wuhan, China.
-
The intelligence was based on a combination of public-domain research and classified investigations under the code name “Saaremaa.”
-
Merkel’s administration allegedly buried the findings, with her successor Olaf Scholz continuing the suppression, ensuring the information remained hidden from the public until now.
Diving Deeper:
Journalist Alex Berenson detailed the shocking revelations in his Substack op-ed, underscoring how “the American media is doing its best to ignore the biggest news this week.” Berenson criticized legacy media outlets for fixating on the five-year anniversary of COVID-19 while sidestepping the implications of newly surfaced intelligence.
According to Berenson, German intelligence reached its high-confidence conclusion after analyzing public materials and conducting covert operations. “The material… indicated that there had been some risky research methods used there [at the Wuhan Institute of Virology], compounded by breaches of laboratory safety rules… [and] so-called gain-of-function experiments, in which viruses occurring in nature are manipulated [to become more dangerous or transmissible],” he wrote.
Rather than alert the world to the evidence, Merkel chose to suppress it. Berenson sarcastically noted, “Who immediately told the world of the findings and demanded a full investigation into what China’s totalitarian government knew and when it knew it? Nah, I’m funning you. Angela stuffed that report in a drawer and got back to doing what she did best, destroying Germany’s industrial base to make Greta Thunberg happy.”
The refusal to disclose this intelligence aligns with a broader pattern of deception from both governmental and media institutions, which spent years dismissing the lab leak hypothesis as a conspiracy theory. Berenson noted that during early 2020, “Dr. Anthony S. Fauci and Peter Daszak… were gently steering their fellow scientists towards a conclusion that COVID’s origins were 100 billion zillion percent natural.”
Even after Merkel left office in 2021, Scholz’s government continued to keep the intelligence under wraps. “The BND told her replacement, Olaf Scholz, ‘without the results finding their way to the public’ — as the British newspaper The Telegraph delicately put it,” Berenson wrote. Now that the findings have emerged, the German government has not denied the reports, leaving Berenson to conclude, “There’s about a 100 to 100 percent chance they’re true.”
The final takeaway? “We all sorta knew this already, right? Both the lab leak and the coverup,” Berenson observed. “But there’s knowing and there’s knowing. And it looks like the same American news outlets that spent 2020 and 2021 lying (or, at best, being hopelessly credulous) about China and COVID still aren’t ready to come clean.”
As new evidence continues to surface, the question remains: Will legacy media and world leaders finally acknowledge the lab leak theory as fact, or will they continue to deflect responsibility and protect their preferred narratives?
Censorship Industrial Complex
How America is interfering in Brazil and why that matters everywhere. An information drop about USAID

USAID Corruption & Brazil’s Elections w/ Nikolas Ferreira & Mike Benz | PBD Podcast
If you’re reading this you’re probably aware that there’s an information war going on. Not the battle between the corporate media vs the new independent journalists. That’s more of a technological and a new media story. The real battle isn’t only between the players, it’s between the information each side is sharing with their audiences.
The corporate world looks down on independent media. They use words like disinformation and misinformation and conspiracy. What they don’t do very often is examine the information being shared and present their own take. In fact, often they don’t share the information at all.
This leaves corporate media faithful in a disadvantaged position. They’re angry because they can’t understand why the world is changing (for the worse in their opinion). They won’t give up their corporate addiction because they’ve become intrenched in the belief the independent start ups are sharing misinformation, disinformation, and conspiracy theories. Because their corporate sources of information choose to ignore or criticize information without presenting a more informed and researched version themselves, their followers are completely missing out on many of the biggest stories that are shaping the century we’re struggling through.
This podcast is a perfect example. Chances are those who ignore independent media have no idea who Patrick Bet David is. That means they’re very unlikely to know anything about Mike Benz. Benz has been revealing secrets of the deep state for years. Recently he’s picked up massive audiences as he makes sense of what’s happening in America and around the world. (Especially with USAID) PBD also talks to Brazilian social media sensation Niklas Ferreira who has a perspective of politics in South America’s largest and most important nation unlike anything you’ll see in the corporate media.
This podcast is fascinating and it answers a lot of questions, not just about America and Brazil, but about the US deep state efforts to control political movements everywhere.
From the PBD Podcast
Patrick Bet-David sits down with Nikolas Ferreira and Mike Benz to dissect the deep connections between USAID, Brazilian corruption, and the political battle between Lula and Bolsonaro.
Ferreira, one of Brazil’s most outspoken conservative voices, exposes how foreign influence and NGOs may be shaping Brazil’s political landscape, while Benz, an expert in geopolitical strategy, unpacks the hidden power dynamics between Washington and Latin America.


A Look at Canada’s Import Tariffs

Leading proponent of Alberta Independence predicts provincial referendum in 2025

Time to finally change the Canada Health Act for the sake of patients

Latest dire predictions about Carney’s emissions cap

Possible Criminal Charges for US Institute for Peace Officials who barricade office in effort to thwart DOGE

It’s time to end supply management

CMHC dished out $30 million in bonuses in 2024
-
 Alberta2 days ago
Alberta2 days agoAlberta Institute urging Premier Smith to follow Saskatchewan and drop Industrial Carbon Tax
-
 Alberta2 days ago
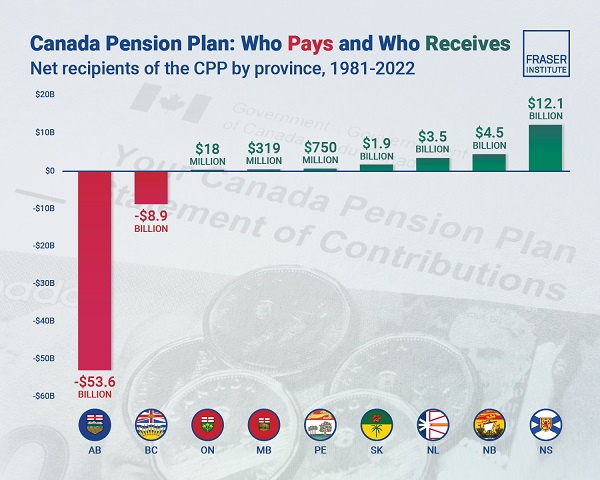
Alberta2 days agoAlbertans have contributed $53.6 billion to the retirement of Canadians in other provinces
-
 Health2 days ago
Health2 days agoHow the once-blacklisted Dr. Jay Bhattacharya could help save healthcare
-
 2025 Federal Election2 days ago
2025 Federal Election2 days agoFool Me Once: The Cost of Carney–Trudeau Tax Games
-
 Addictions2 days ago
Addictions2 days agoShould fentanyl dealers face manslaughter charges for fatal overdoses?
-
 Alberta16 hours ago
Alberta16 hours agoPhoto radar to be restricted to School, Playground, and Construction Zones as Alberta ends photo radar era
-
 Alberta16 hours ago
Alberta16 hours agoProvince pumping $100 million into Collegiates and Dual-Credit hands-on learning programs
-
 Fraser Institute15 hours ago
Fraser Institute15 hours agoPremier Eby seeks to suspend democracy in B.C.