Censorship Industrial Complex
Biden Agencies Have Resumed Censorship Collaboration With Big Tech, Dem Senate Intel Chair Says


 From the Daily Caller News Foundation
From the Daily Caller News Foundation
By JASON COHEN
Agencies in President Joe Biden’s administration have resumed their perceived disinformation censorship collaboration with social media companies, Senate Intelligence Committee Chairman Mark Warner told reporters at a recent security conference, Nextgov/FCW reported.
The administration stopped “misinformation” censorship collaboration with social media platforms after a July Missouri v. Biden ruling to prevent federal agencies from coordinating with social media companies, but recently restarted this work, Warner # reporters, according to Nextgov. He said the cooperation resumed as the Supreme Court heard oral arguments in the case, now called Murthy v. Missouri, in March, where multiple justices indicated they supported the Biden administration’s viewpoint that it has the right to work with platforms to combat what it believes is harmful content.
Democrat Senator Mark Warner says there’s a “voluntary agreement about disinformation and misinformation in elections” between “all 20 of the major social media companies” pic.twitter.com/YmIyAuJBrw
— RNC Research (@RNCResearch) April 21, 2024
“There seemed to be a lot of sympathy that the government ought to have at least voluntary communications with [the companies],” Warner said, according to Nextgoc. He also reportedly called on the Biden administration to take strong action against any foreign countries that try to interfere in the 2024 election.
The agencies include the Department of Homeland Security’s Cybersecurity and Infrastructure Security Agency (CISA) and the Federal Bureau of Investigation (FBI), according to NextGov.
“If the bad guy started to launch AI-driven tools that would threaten election officials in key communities, that clearly falls into the foreign interference category,” he added.
A district court judge issued an injunction in July preventing certain officials in agencies from the Department of Health and Human Services (HHS) to the FBI from communicating with social media platforms to censor speech, characterizing the government conduct exposed by the plaintiffs in the case as arguably “the most massive attack against free speech in United States’ history.”
Justices Sonia Sotomayor, Elena Kagan and Ketanji Brown Jackson, expressed concern during March oral arguments about restricting the government’s ability to persuade companies to take action when necessary, such as when terrorists disseminate speech on a platform.
The justices also questioned whether the plaintiffs could prove their platforms censored their speech as a direct result of the government.
Facebook executives believed they were engaged in a “knife fight” with Biden’s White House on COVID-19 censorship, according to a recent House Judiciary Committee report. Biden accused the platform of “killing people” in July 2021 for not censoring so-called COVID-19 misinformation, and unearthed WhatsApp messages between Facebook executives revealed that they were unhappy about the president’s remarks.
Warner, the White House and the FBI did not immediately respond to the Daily Caller News Foundation’s request for comment. CISA declined to comment, but notified the DCNF about an Election Security hearing in the coming weeks with the agency’s Director, Jen Easterly.


By
Mark Carney dodges Epstein jabs in Hamilton while reviving failed Liberal plans for speech control via Bill C-36 and Bill C-63.
|
It was supposed to be a routine campaign pit stop, the kind of low-stakes political affair where candidates smile like used car salesmen and dish out platitudes thicker than Ontario maple syrup. Instead, Mark Carney found himself dodging verbal bricks in a Hamilton hall, facing hecklers who lobbed Jeffrey Epstein references like Molotovs. No rebuttal, no denial. Just a pivot worthy of an Olympic gymnast, straight to the perils of digital discourse.
“There are many serious issues that we’re dealing with,” he said, ignoring the criticism that had just lobbed his way. “One of them is the sea of misogyny, antisemitism, hatred, and conspiracy theories — this sort of pollution online that washes over our virtual borders from the United States.”
Ah yes, the dreaded digital tide. Forget inflation or the fact that owning a home now requires a GoFundMe. According to Carney, the real catastrophe is memes from Buffalo.
The Ghost of Bills Past
Carney’s new plan to battle the internet; whatever it may be, because details are apparently for peasants, would revive a long-dead Liberal Party obsession: regulating online speech in a country that still pretends to value free expression.
It’s an effort so cursed, it’s been killed more times than Jason Voorhees. First, there was Bill C-36, which flopped in 2021. Then came its undead cousin, Bill C-63, awkwardly titled the Online Harms Act, which proposed giving the Canadian Human Rights Commission the power to act as digital inquisitors, sniffing out content that “foments detestation or vilification.”
Naturally, it died too, not from public support, but because Parliament decided it had better things to do, like not passing it in time.
But as every horror franchise teaches us, the villain never stays away for long. Carney’s speech didn’t include specifics, which is usually code for “we’ll make it up later,” but the intent is clear: the Liberals are once again oiling up the guillotine of speech regulation, ready to let it fall on anything remotely edgy, impolite, or, God forbid, unpopular.
“Won’t Someone Think of the Children?”
“The more serious thing is when it affects how people behave — when Canadians are threatened going to their community centers or their places of worship or their school or, God forbid, when it affects our children,” Carney warned, pulling the emergency brake on the national sympathy train. It’s the same tired tactic every aspiring control freak uses, wrap the pitch in the soft fuzz of public safety and pray nobody notices the jackboot behind the curtain.
Nothing stirs the legislative loins like invoking the children. But vague terror about online contagion infecting impressionable minds has become the go-to excuse for internet crackdowns across the Western world. Canada’s Liberals are no different. They just dress it up and pretend it’s for your own good.
“Free Speech Is Important, But…”
Former Heritage Minister Pascale St-Onge, doing her best impression of a benevolent censor, also piped up earlier this year with a classic verbal pretzel: “We need to make sure [freedom of expression] exists and that it’s protected. Yet the same freedom of expression is currently being exploited and undermined.”
Protecting free speech by regulating it is the sort of logic that keeps satire writers out of work.
St-Onge’s lament about algorithms monetizing debate sounds suspiciously like a pitch from someone who can’t get a word in on X. It’s the familiar cry of technocrats and bureaucrats who can’t fathom a world where regular people might say things that aren’t government-approved. “Respect is lacking in public discourse,” she whined on February 20. She’s right. People are tired of pretending to respect politicians who think governing a country means babysitting the internet.
|
|
|
|
Powerful forces want to silence independent voices online
|
|
Governments and corporations are working hand in hand to control what you can say, what you can read; and soon, who you are allowed to be.
New laws promise to “protect” you; but instead criminalize dissent.
Platforms deplatform, demonetize, and disappear accounts that step out of line.
AI-driven surveillance tracks everything you do, feeding a system built to monitor, profile, and ultimately control.
Now, they’re pushing for centralized digital IDs; a tool that could link your identity to everything you say and do online. No anonymity. No privacy. No escape.
This isn’t about safety, it’s about power.
If you believe in a truly free and open internet; where ideas can be debated without fear, where privacy is a right, and where no government or corporation dictates what’s true; please become a supporter.
By becoming a supporter, you’ll help us:
We don’t answer to advertisers or political elites.
If you can, please become a supporter. It takes less than a minute to set up, you’ll get a bunch of extra features, guides, analysis and solutions, and every donation strengthens the fight for online freedom.
|
|


 Dan Knight
Dan Knight
The former central banker, who now postures as a man of the people, made it clear that if the Liberals are re-elected, the federal government will intensify efforts to regulate what Canadians are allowed to see, say, and share online.
At a campaign rally in Hamilton, Ontario, Liberal leader Mark Carney unveiled what can only be described as a coordinated assault on digital freedom in Canada. Behind the slogans, applause lines, and empty rhetoric about unity, one portion of Carney’s remarks stood out for its implications: a bold, unapologetic commitment to controlling online speech under the guise of “safety” and “misinformation.”
“We announced a series of measures with respect to online harm… a sea of misogyny, anti-Semitism, hatred, conspiracy theories—the sort of pollution that’s online that washes over our virtual borders from the United States.”
He then made clear his intention to act:
“My government, if we are elected, will be taking action on those American giants who come across [our] border.”
The former central banker, who now postures as a man of the people, made it clear that if the Liberals are re-elected, the federal government will intensify efforts to regulate what Canadians are allowed to see, say, and share online. His language was deliberate. Carney condemned what he called a “sea of misogyny, anti-Semitism, hatred, conspiracy theories” polluting Canada’s internet space—language borrowed directly from the Trudeau-era playbook. But this wasn’t just a moral denunciation. It was a legislative preview.
Carney spoke of a future Liberal government taking “action on those American giants who come across our borders.” Translation: he wants to bring Big Tech platforms under federal control, or at least force them to play the role of speech enforcers for the Canadian state. He blamed the United States for exporting “hate” into Canada, reinforcing the bizarre Liberal narrative that the greatest threat to national unity isn’t foreign actors like the CCP or radical Islamists—it’s Facebook memes and American podcasts.
But the most revealing moment came when Carney linked online speech directly to violence. He asserted that digital “pollution” affects how Canadians behave in real life, specifically pointing to conjugal violence, antisemitism, and drug abuse. This is how the ground is prepared for censorship: first by tying speech to harm, then by criminalizing what the state deems harmful.
What Carney didn’t say is just as important. He made no distinction between actual criminal incitement and political dissent. He offered no assurance that free expression—a right enshrined in Canada’s Charter of Rights and Freedoms—would be respected. He provided no definition of what constitutes a “conspiracy theory” or who gets to make that determination. Under this framework, any criticism of government policy, of global institutions, or of the new technocratic order could be flagged, throttled, and punished.
And that’s the point.
Mark Carney isn’t interested in dialogue. He wants obedience. He doesn’t trust Canadians to discern truth from fiction. He believes it’s the job of government—his government—to curate the national conversation, to protect citizens from wrongthink, to act as referee over what is and isn’t acceptable discourse. In short, he wants Ottawa to become the Ministry of Truth.
Why They Don’t Actually Care About Antisemitism
The Liberal establishment talks a big game about fighting hate—but when it comes to actual antisemitic violence, they’ve shown nothing but selective enforcement and political cowardice.
Let’s look at the facts.
In 2023, B’nai Brith Canada recorded nearly 6,000 antisemitic incidents, including 77 violent attacks—from firebombed synagogues to shots fired at Jewish schools in Montreal and Toronto. This wasn’t a marginal increase. It was a 208% spike in violent antisemitism in a single year.
Statistics Canada echoed the same alarm bells. Jews—who make up just 1% of Canada’s population—were the victims of 70% of all religiously motivated hate crimes. That’s nearly 900 recorded incidents, up 71% from the previous year. Then came October 2023, when Hamas launched its attack on Israel—and the wave of hate turned into a tsunami: a 670% increase in antisemitic incidents across the country. Jewish schools, synagogues, and community centers were hit with bomb threats, arson attempts, and intimidation campaigns. This was a national security issue, not just a policing matter.
And yet, the government’s response? Virtually nonexistent.
Case in point: the Montreal Riot, November 2024. A 600-person mob, waving anti-NATO and pro-Palestinian banners, turned violent—setting fires, smashing windows, and attacking police. Amid this chaos, a man was filmed screaming “Final Solution”—a direct reference to the Nazi plan to exterminate the Jews. It went viral. There was no ambiguity, no misunderstanding. It was a public call for genocide.
So what happened?
Three arrests. None for hate crimes. None related to antisemitism. Montreal Police Chief Fady Dagher insisted there were “no confirmed antisemitic acts,” and as of early 2025, no hate crime charges have been filed against the individual caught on camera.
That man, as it turns out, owned a Second Cup franchise. His punishment? His café was shut down by the company. Not by law enforcement. Not by hate crime investigators. A corporate HR department showed more backbone than Canada’s justice system.
And this is what reveals the truth: they don’t care. They’ll enforce hate speech laws when it’s politically convenient—when it can be used to silence critics, crush dissent, or placate woke constituencies. But when Jewish communities are being threatened, attacked, and terrorized? The same laws suddenly go limp. The same political class that claims to protect minorities becomes paralyzed. They won’t touch it. Because confronting real antisemitism would require standing up to their political allies in activist circles, university campuses, and radical protest movements.
This isn’t an accident. It’s a pattern.
The Liberals aren’t weak on antisemitism because they’re unaware of it. They’re weak on it because they don’t see political value in enforcing the law when it conflicts with their ideological allies. Their obsession isn’t with hate speech—it’s with controlling “wrong” speech. And what qualifies as “wrong” isn’t defined by law or principle. It’s defined by what the Liberal establishment deems unacceptable.
Their target isn’t violent bigotry. It’s dissent. They’ll chase down citizens for questioning carbon taxes or criticizing globalist policy—but when Jewish schools get shot at, or someone calls for genocide in the street, they shrug.
This isn’t leadership. It’s selective justice. And it proves, beyond any doubt, that their agenda was never about protecting Canadians. It was always about protecting control.
The Online Harms Act: Carney’s Blueprint for Speech Control
This isn’t hypothetical. Mark Carney’s remarks in Hamilton mirror the exact logic and intent behind the Online Harms Act (Bill C-63)—legislation drafted under the Liberal banner and introduced in 2024 that pushes Canada into territory no free society should accept.
At its core, Bill C-63 hands the federal government sweeping powers to police digital speech. It creates a Digital Safety Commission, an unelected bureaucratic authority empowered to monitor, investigate, and punish online platforms and individuals for content deemed “harmful.” That word—harmful—is never concretely defined. It includes things like “hate speech,” “conspiracy theories,” and vague notions of “harm to children,” but it’s written broadly enough to be used as a political weapon.
The most chilling provision? Preemptive imprisonment. Under this law, Canadians could be jailed for up to a year—without having committed a crime—if a judge believes they might post something harmful in the future. This isn’t law enforcement. This is thought policing.
Carney didn’t just echo this approach—he amplified it. In his Hamilton rally, he described the internet as being flooded with “misogyny, anti-Semitism, hatred, conspiracy theories,” and laid blame on foreign content “washing over our borders from the United States.” He didn’t argue for open debate or for empowering users to challenge dangerous ideas. He argued for the state to intervene and shut them down.
He told Canadians that these ideas are “changing how people behave” and claimed his government will go after “those American giants” that allow this content to circulate. There’s no ambiguity here: this is a public declaration that a Liberal government under Mark Carney intends to censor, de-platform, and penalize dissenting views. Not illegal ones—just ones they don’t like.
And this isn’t new for him. Back in 2022, during the Freedom Convoy, Carney referred to protesters as committing “sedition” and demanded the government “thoroughly punish” them. These weren’t violent rioters or foreign agitators—these were working-class Canadians honking their horns and standing in the cold, protesting vaccine mandates. For Carney, their real crime was disobedience.
Carney’s view of speech is simple: if it challenges the ruling order, it’s dangerous. And now, with Bill C-63 on the table and Carney at the helm, he’s building the legal infrastructure to lock down the digital public square—not to protect Canadians from violence, but to protect the Liberal establishment from criticism.
That law is real. Carney’s agenda is real. And if he wins, enforcement is coming.
Final thoughts
This is the Canada Mark Carney envisions—one where citizens can’t speak freely online without first checking their views against government guidelines. A country where speech is no longer a right but a privilege granted by bureaucrats. A country where opposition isn’t argued with, it’s labeled harmful and erased.
There was a time when Liberals championed civil liberties. That era is over. The new Liberalism is authoritarian—cloaked in the language of safety and inclusion, but animated by control. Carney’s rally in Hamilton wasn’t a policy rollout. It was a warning to anyone who still thinks they live in a country where dissent is allowed.
They don’t want to fight hate. They want to define “wrong” speech—and then eliminate it. And by “wrong,” they mean anything the Liberal establishment disapproves of. Criticize the government, question the orthodoxy, challenge the state’s narrative, and you’ll be branded a threat. Not a citizen. Not a participant. A threat.
So here we are.
The speech laws are written. The censors are waiting. And Mark Carney is ready to pull the trigger.
This election isn’t about tax credits or campaign slogans. It’s about whether Canada remains a free country or slides deeper into soft tyranny, one regulation, one commission, one silenced voice at a time.
There is a choice. And the choice is this: bring it home—restore freedom, restore sanity, restore this country.
Or: hand the keys to the same people who think you’re the problem for having the nerve to think for yourself.
Subscribe to The Opposition with Dan Knight .
For the full experience, upgrade your subscription.


Province introducing “Patient-Focused Funding Model” to fund acute care in Alberta
Mark Carney To Ban Free Speech if Elected

Musk Slashes DOGE Savings Forecast By 85%

What Trump Says About Modern U.S. And What Carney Is Hiding About Canada
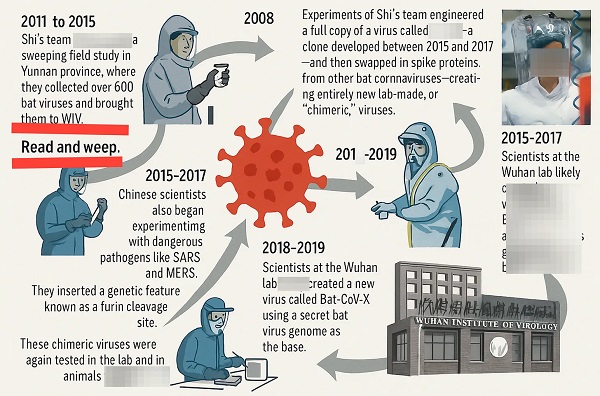
BLOCKBUSTER REPORT: Canada’s ties to Wuhan Institute of Virology and creation of COVID uncovered by Sam Cooper of The Bureau

Taxpayers urge federal party leaders to drop home sale reporting to CRA

‘Sadistic’ Canadian murderer claiming to be woman denied transfer to female prison
-
 Business23 hours ago
Business23 hours agoDOGE Is Ending The ‘Eternal Life’ Of Government
-
 espionage15 hours ago
espionage15 hours agoEx-NYPD Cop Jailed in Beijing’s Transnational Repatriation Plot, Canada Remains Soft Target
-
 2025 Federal Election2 days ago
2025 Federal Election2 days agoRCMP Whistleblowers Accuse Members of Mark Carney’s Inner Circle of Security Breaches and Surveillance
-
 2025 Federal Election1 day ago
2025 Federal Election1 day agoNeil Young + Carney / Freedom Bros
-
 2025 Federal Election23 hours ago
2025 Federal Election23 hours agoTucker Carlson Interviews Maxime Bernier: Trump’s Tariffs, Mass Immigration, and the Oncoming Canadian Revolution
-
 Health2 days ago
Health2 days agoTrump admin directs NIH to study ‘regret and detransition’ after chemical, surgical gender transitioning
-
 2025 Federal Election22 hours ago
2025 Federal Election22 hours agoCanada drops retaliatory tariffs on automakers, pauses other tariffs
-
 2025 Federal Election2 days ago
2025 Federal Election2 days agoMEI-Ipsos poll: 56 per cent of Canadians support increasing access to non-governmental healthcare providers